https://cdn-images-1.medium.com/max/800/1*3tUB6KRfE-FapwbH4Lz0Vg.png
Facets은 PAIR(People + AI Research) 라는 계획의 일환으로 구글에서 내놓은 오픈소스 시각화툴이다. 머신러닝 데이터셋에 대한 이해와 분석을 돕는 도구로, 2개의 시각화 도구로 구성된다.
Facets Overview
이름에서 짐작할 수 있듯이 이 시각화 도구는 전체 데이터셋의 개요와 데이터 각각의 특징 면면에 대한 감을 제공한다. 개요에서는 각각의 특징에 대한 통계를 제공하고 훈련 및 검증 데이터셋을 비교한다.
Facets Dive
더 많은 정보를 얻기 위해 개별 특징에 대해 상세히 살펴볼 수 있고, 대규모의 데이터도 대화형 콘솔을 통해 한 번에 살펴볼 수 있다. 이 도구는 Polymer 웹 컴포넌트로 구현이 되었고, Typescript 가 지원되고, 주피터 노트북이나 웹페이지에 손쉽게 삽입될 수 있다.
Usage & Installation
FACETS은 2가지 방식으로 이용가능하다.
- Web App - 아래의 데모페이지에서 바로 사용이 가능하다. 설치없이 웹브라우저 상에서 여러분의 데이터셋을 시각화시킬 수 있다. Facets - Visualizations for ML datasets
- Within Jupyter Notebooks/Colaboratory - 주피터 노트북에서 FACETS 구현이 가능하다. 설치와 관련한 상세한 내용은 Github Repository 에서 확인가능하다.
Installation
먼저 주피터 노트북에서 Facets 를 사용하기 위해서는 다음 2가지 사항을 고려해야 한다.
1. 노트북에서 Facets Overview python code 가 로딩되는 패스를 노트북 커널이 구동되는 경로로 변경한다.
2. 구글의 데이터 교환 포맷인 Protocol Buffers python runtime library 가 설치되어 있어야 한다. 아래 링크를 참고하여 설치한다. https://github.com/google/protobuf/tree/master/python
아나콘다 환경의 경우 다음 링크를 참고한다. https://anaconda.org/anaconda/protobuf
(tfKeras) founder@hilbert:~/tfKeras/facets$ conda install -c anaconda protobuf Solving environment: done ## Package Plan ## environment location: /home/founder/anaconda3/envs/tfKeras added / updated specs: - protobuf The following packages will be downloaded: package | build ---------------------------|----------------- protobuf-3.6.1 | py36he6710b0_0 616 KB anaconda libprotobuf-3.6.1 | hd408876_0 4.1 MB anaconda ------------------------------------------------------------ Total: 4.7 MB The following NEW packages will be INSTALLED: libprotobuf: 3.6.1-hd408876_0 anaconda protobuf: 3.6.1-py36he6710b0_0 anaconda Proceed ([y]/n)? y Downloading and Extracting Packages protobuf-3.6.1 | 616 KB | ############################################################################################## | 100% libprotobuf-3.6.1 | 4.1 MB | ############################################################################################## | 100% Preparing transaction: done Verifying transaction: done Executing transaction: done | cs |
대규모의 데이터를 Dive 에서 시각화하기 위해서는 노트북 서버를 IOPub data rate 를 증가시켜 구동해야 한다. 다음과 같이 실행하면 된다.
$ jupyter notebook --NotebookApp.iopub_data_rate_limit=10000000 --no-browser --ip=0.0.0.0 | cs |
Code Installation
$ git clone https://github.com/PARI-code/facets $ cd facets | cs |
Building the Visualizations
시각적인 면에 변화를 주고 싶다면, 다음과 같이 한다.
1. Install bazel
https://anaconda.org/conda-forge/bazel
$ conda install -c conda-forge bazel Solving environment: done ## Package Plan ## environment location: /home/founder/anaconda3/envs/tfKeras added / updated specs: - bazel The following packages will be downloaded: package | build ---------------------------|----------------- bazel-0.20.0 | 0 112.4 MB conda-forge openjdk-11.0.1 | h14c3975_1014 175.4 MB conda-forge ------------------------------------------------------------ Total: 287.8 MB The following NEW packages will be INSTALLED: bazel: 0.20.0-0 conda-forge openjdk: 11.0.1-h14c3975_1014 conda-forge The following packages will be UPDATED: certifi: 2018.11.29-py36_0 anaconda --> 2018.11.29-py36_1000 conda-forge openssl: 1.0.2p-h14c3975_0 anaconda --> 1.0.2p-h14c3975_1002 conda-forge The following packages will be DOWNGRADED: ca-certificates: 2018.12.5-0 anaconda --> 2018.11.29-ha4d7672_0 conda-forge Proceed ([y]/n)? y Downloading and Extracting Packages bazel-0.20.0 | 112.4 MB | ################################################################################################################################################################################################## | 100% openjdk-11.0.1 | 175.4 MB | ################################################################################################################################################################################################## | 100% Preparing transaction: done Verifying transaction: done Executing transaction: done | cs |
2. 다음과 같이 빌드를 진행한다 (facets 의 최상위 디렉토리에서 진행한다)
/facets$ bazel build facets:facets_jupyter Extracting Bazel installation... Starting local Bazel server and connecting to it... INFO: Invocation ID: 37a25288-669f-4773-90a4-f3ba1023b7df INFO: Analysed target //facets:facets_jupyter (176 packages loaded, 35187 targets configured). INFO: Found 1 target... | cs |
Data
데모페이지의 데이터를 가지고 작업을 할 수도 있지만, 여기서는 다른 데이터셋을 가지고 진행하기로 한다. 대출 예측 데이터셋을 사용할하여 상환 여부를 예측을 해보자. 해당 파일은 하단 링크에서 다운받을 수 있다.
해당 데이터셋은 이미 훈련셋과 검증셋으로 구분되어 있다. 데이터를 로딩해보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # Load UCI census train and test data into dataframes. import pandas as pd features = ["Loan_ID", "Gender", "Married", "Dependents", "Education", "Self_Employed", "ApplicantIncome", "CoapplicantIncome", "LoanAmount", "Loan_Amount_Term", "Credit_History", "Property_Area", "Loan_Status"] train_data = pd.read_csv( 'train.csv', names=features, sep=r'\s*,\s*', engine='python', na_values="?") test_data = pd.read_csv( 'test.csv', names=features, sep=r'\s*,\s*', skiprows=[0], engine='python', na_values="?") | cs |
그러면 이 데이터를 가지고 어떻게 Facets 를 사용하지는 살펴보자.
FACETS Overview
데이터의 다양한 항목에 대한 값의 분포를 살펴볼 수 있으며, 그 분포는 훈련 데이터셋과 검증 데이터셋 상호간에 비교 가능하다. 취득가능한 정보들은 다음과 같다.
- 중앙값, 최빈값, 표준편차 등의 통계 자료
- 해당 컬럼의 최소 및 최대값
- 손실된 데이터
- 제로 값을 가지는 값
통계를 계산하기 위해서는 GenericFeatureStatisticsGenerator() 함수를 사용하면 된다.
1 2 3 4 5 6 7 8 9 10 11 12 | # Add the path to the feature stats generation code. import sys sys.path.insert(0, '/home/founder/tfKeras/facets/facets_overview/python') # Create the feature stats for the datasets and stringify it. import base64 from generic_feature_statistics_generator import GenericFeatureStatisticsGenerator gfsg = GenericFeatureStatisticsGenerator() proto = gfsg.ProtoFromDataFrames([{'name': 'train', 'table': train_data}, {'name': 'test', 'table': test_data}]) protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8") | cs |
다음의 코드로 노트북에서 시각화 결과를 볼 수 있다.
1 2 3 4 5 6 7 8 9 10 | # Display the facets overview visualization for this data from IPython.core.display import display, HTML HTML_TEMPLATE = """<link rel="import" href="facets-dist/facets-jupyter.html" > <facets-overview id="elem"></facets-overview> <script> document.querySelector("#elem").protoInput = "{protostr}"; </script>""" html = HTML_TEMPLATE.format(protostr=protostr) display(HTML(html)) | cs |
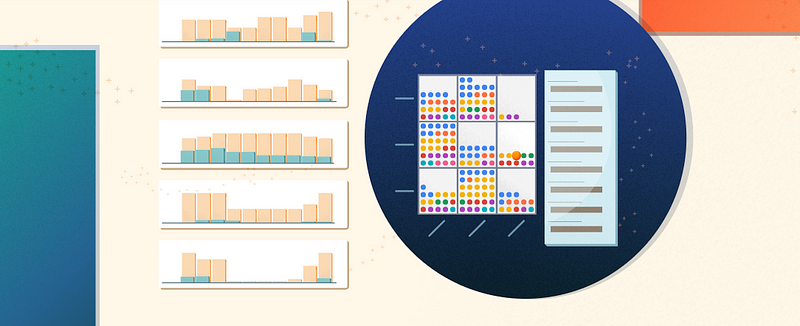
Shift+Enter 를 입력하면, 아래와 같은 깔끔한 대화형 시각화 화면을 볼 수 있다. 아래는 대출 예측 데이터셋의 Facets 개요 화면으로 5개의 특성을 살펴볼 수 있다. 빨간 숫자의 경우 문제가 되는 지점을 나타낸다. 오른쪽의 히스토그램은 훈련 데이터 (파란색)과 검증 데이터 (오렌지색)의 분포를 보여준다.

아래 이미지는 데이터셋의 8개의 특징 카테고리를 보여준다.

FACETS Dive
Facets Dive는 데이터셋의 서로 다른 특징등을 데이터포인트 사이의 관계 등을 살펴볼 수 있는 직관적인 인터페이스와 커스토마이징을 제공한다.
Facets Dive 에서는 특징값에 따라 각 데이터 포인트의 위치, 색상, 그리고 시각적인 표현등을 조절할 수 있다. 데이터포인트가 연관성 있는 이미지를 가지고 있다면, 프리젠테이션용으로 그 이미지를 사용할 수도 있다. Dive 시각화를 사용하기 위해서는 데이터가 아래와 같이 JSON 포맷으로 변환되어야 한다.
1 2 3 4 5 6 7 8 9 10 11 | # Display the Dive visualization for the training data. from IPython.core.display import display, HTML jsonstr = train.to_json(orient='records') HTML_TEMPLATE = """<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/master/facets-dist/facets-jupyter.html"> <facets-dive id="elem" height="600"></facets-dive> <script> var data = {jsonstr}; document.querySelector("#elem").data = data; </script>""" html = HTML_TEMPLATE.format(jsonstr=jsonstr) display(HTML(html)) | cs |
위 코드를 실행하면 다음과 같은 결과를 볼 수 있다. 단, 이 경우 위 라인을 개요 위로 올려서 실행해야 한다.

아래와 같이 단일변수 또는 이변수 분석 등을 포함하여 다양한 분석이 가능하다.



이상 보았듯이 FACETS은 간편하고 직관적인 데이터셋 분석환경을 제시한다. 유일한 단점이라고는 크롬에서만 사용가능하다는 점 정도이다. 특히 아래와 같이 소소한 라벨링 오류까지 잡아낼 수 있다는 점에서 무척 매력적인 툴이다.
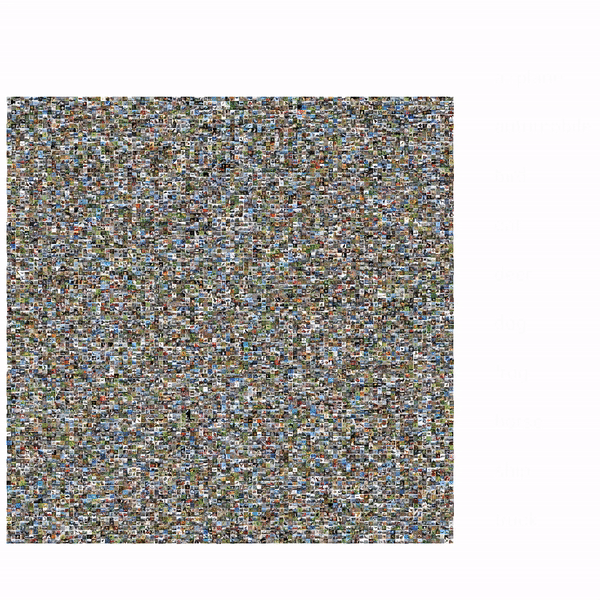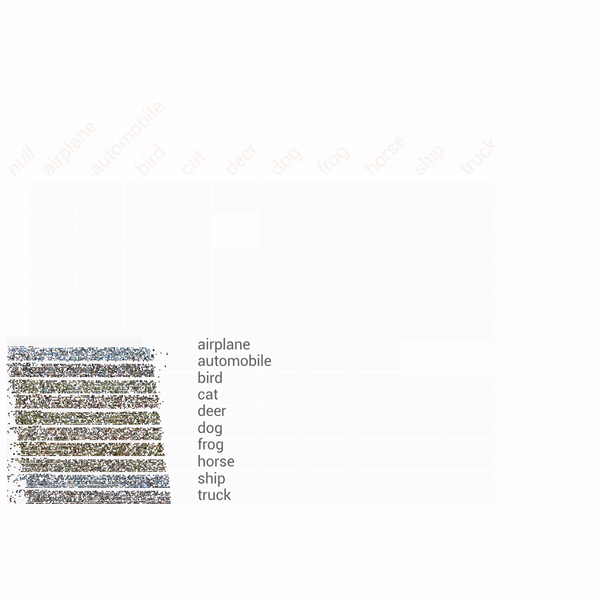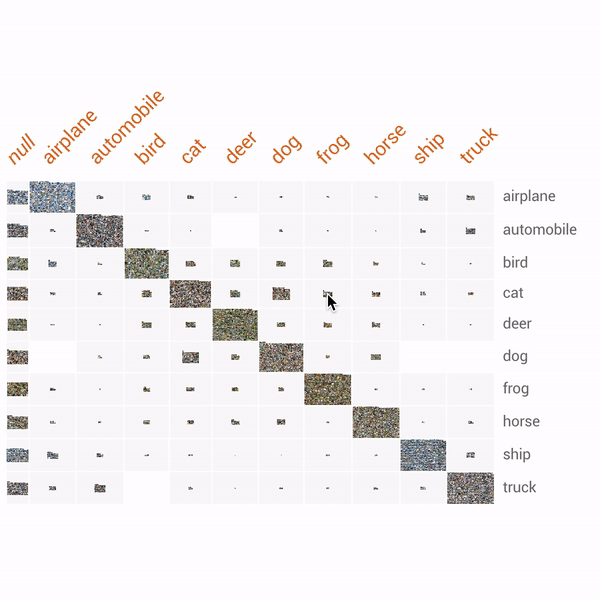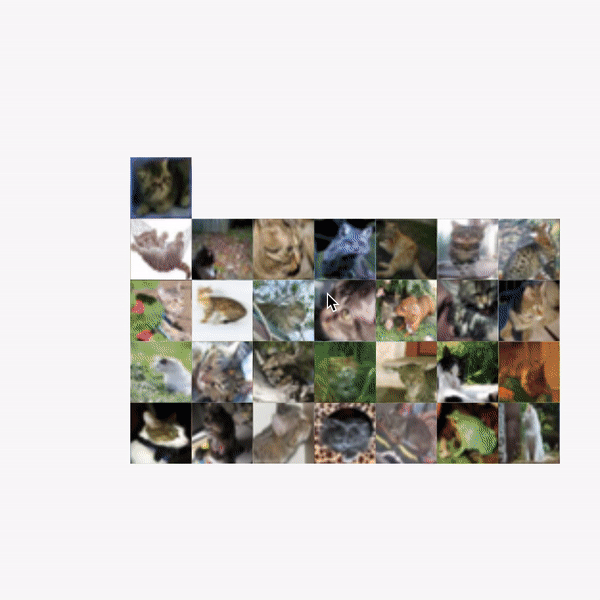
https://cdn-images-1.medium.com/max/800/1*VfkUBpXdGNIsK_RKT-ct1Q.gif
'프로그래밍 Programming' 카테고리의 다른 글
| 텔레그램 봇 만들기 Your first Telegram Bot (0) | 2019.02.15 |
|---|---|
| 우분투 18.04에 워드프레스 설치하기 How To Install WordPress with LEMP on Ubuntu 18.04 (0) | 2019.02.14 |
| 트럼프 대통령 연설문 자동 요약하기 Automatically Summarize Trump’s State of the Union Address (0) | 2019.02.09 |
| 우분투 아나콘다서버에 플라스크 앱 배포하기 Deploy Flask apps using Anaconda on Ubuntu Server (0) | 2019.01.21 |
| Conda 가상 환경으로 PyTorch 설치하기 (0) | 2019.01.19 |