Airplane Image Classification using a Keras CNN
Data Acquisition
여기서 사용될 데이터셋은 Kaggle 에서 가져온다. 해당 데이터셋은 rhammel 라는 사용자가 업로드한 것으로, 32,000개의 라벨링된 비행기의 위성 사진이다.
먼저 여기로 이동하여 “planesnet.zip” 을 다운로드 받는다.

다운로드받은 파일의 압축을 풀어보면,

“0__20140723_181317_0905__-122.14328662_37.697282118.png” 와 같은 이름으로 구성된 32,000개의 이미지 파일을 확인할 수 있을 것이다.
Data Preprocessing
앞선 데이터를 ML 알고리즘에 활용가능하게 다듬는 작업을 데이터 프로세싱이라고 한다. 다운로드받은 이미지를 ML 알고리즘이 데이터를 해석할 수 있도록 구조화시키는 작업이다.
먼저 필요한 라이브러리를 가져온다. 다음과 같다.
1 2 3 4 5 | # Imports import glob import numpy as np import os.path as path from scipy import misc | cs |
IMAGE_PATH 에 이미지 파일이름을 검색한다.
1 2 3 | # IMAGE_PATH should be the path to the downloaded planesnet folder IMAGE_PATH = 'planesnet' file_paths = glob.glob(path.join(IMAGE_PATH, '*.png')) | cs |
이미지를 단일 변수로 집어넣어, numpy 배열로 변환한다.
1 2 3 | # Load the images images = [misc.imread(path) for path in file_paths] images = np.asarray(images) | cs |
/home/founder/anaconda3/envs/tfKeras/lib/python3.6/site-packages/ipykernel_launcher.py:2: DeprecationWarning: `imread` is deprecated! `imread` is deprecated in SciPy 1.0.0, and will be removed in 1.2.0. Use ``imageio.imread`` instead.
이미지 크기를 검색한다.
1 2 3 | # Get image size image_size = np.asarray([images.shape[1], images.shape[2], images.shape[3]]) print(image_size) | cs |
[20 20 3]
image_size 배열을 통해서 이미지의 차원을 알 수 있다. 이 변수를 출력해보면 이미지의 차원이 [20, 20, 3] 임을 알 수 있는데, 이것이 의미하는 바는 데이터셋에 포함된 각각의 이미지는 행과 열이 각각 20 이고 depth가 3 (즉, RGB 3채널을 가진다) 임을 나타낸다. 이러한 숫자들은 해당 이미지의 공간해상도를 정의하는 셈이다.
이제 그 값이 0~1 이 되도록 이미지의 크기를 변경하자.
1 2 | # Scale images = images / 255 | cs |
우리가 작업하는 이미지는 8비트이다. 이 말은 이미지 각 픽셀은 256 (2⁸ = 256) 개의 가능한 값 중 하나를 가진다는 말이다. 0부터 시작하므로 255가 가장 큰 값인 셈이다. 따라서 255로 나누게 되면, 이미지의 값을 0~1 사이로 줄일 수 있다.
그렇게 되면 기존에 128 이라는 정수로 표현되던 값은 128/255 = ~0.502 라는 실수값으로 변경이 된다. 이 단계 이후로는 이미지의 외형은 영구적으로 변경되지 않게 된다는 점이 중요하다.
다음 단계는 이미지 라벨을 검색하는 것이다. 앞서 언급했듯이 데이터셋의 라벨은 사람에 의해 매겨진 것이다. 20*20 픽셀로 이루어진 이미지를 검토한 뒤 만약 비행기 이미지를 포함하고 있으면 “1” (True) 을 그렇지 않다면 “0” (False) 이라는 라벨을 붙인 것이다. 이미지 파일 네임 제일 앞부분이 그 값을 나타내는 것이다.
예를 들어, “0__20140723_181317_0905__-122.14328662_37.697282118.png” 라는 파일 이름의 제일앞의 “0”은 이 이미지에는 비행기가 포함되어 있지 않다는 의미인 셈이다. 다음 코드를 통해 라벨을 추출해낼 수 있다.
1 2 3 4 5 6 7 | # Read the labels from the filenames n_images = images.shape[0] labels = np.zeros(n_images) for i in range(n_images): filename = path.basename(file_paths[i])[0] labels[i] = int(filename[0]) | cs |
전통적인 지도학습에서는 이미지를 "X" 에, 그리고 라벨을 "Y" 로 생각하고 머신러닝 알고리즘은 y=f(x) 와 같이 주어진 이미지에 대한 함수 "f" 를 찾는 것이었다. 다른 말로 하면, 1,200 (20 x 20 x 3 = 1,200) 개의 X 값을 함수 f 를 통해 실행하는 셈이다. 그리고 “plane” 또는 “not plane” 이라는 y 값을 예측하는 것이다.
다음 단계는 데이터를 훈련과 검증 셋트로 나누는 것이다. 이 부분은 특히 중요한데, 왜냐하면 편향되지 않는 방식으로 여러분의 모델을 평가할 수 있는 유일한 방식이기 때문이다. 기본적으로 훈련셋트를 통해 학습하게 되고 (보통 보유하고 있는 이미지의 90% 정도), 검증셋트 (나머지 10%)에서 그 정확도를 평가받는다.
훈련셋트에서만 잘 작동하는 모델은 유용하지도 흥미롭지도 않다. 이를 보통 과적합(over-fit)이라 부른다. 과적합이란 모델이 그 라벨을 외웠다는 의미와 같다. 예를 들면 2 + 2 = 4 라고 외운 학생이 모든 덧셈의 결과가 4라고 가정하는 것과 같다. 이 경우는 실제로 덧셈을 배운 것이 아니라 단지 그 결과만을 외운 것에 불과하다. 아래와 같이 검증 셋트를 만들어서 시뮬레이션을 해보자.
1 2 | # Split into test and training sets TRAIN_TEST_SPLIT = 0.9 | cs |
1 2 3 4 5 | # Split at the given index split_index = int(TRAIN_TEST_SPLIT * n_images) shuffled_indices = np.random.permutation(n_images) train_indices = shuffled_indices[0:split_index] test_indices = shuffled_indices[split_index:] | cs |
1 2 3 4 5 | # Split the images and the labels x_train = images[train_indices, :, :] y_train = labels[train_indices] x_test = images[test_indices, :, :] y_test = labels[test_indices] | cs |
이 분류과정까지 마치면 전처리 단계는 끝난 것이다. 다음 섹션에서는 몇 개 이미지를 시각화해본다.
Data Visualization
데이터 시각화는 훈련 데이터를 검증하고 그것에 담긴 패턴을 감지하는 과정이다. 이미지 데이터의 경우 데이터셋에 담기 일부 이미지를 엿보는 것인데, 파이썬에 익숙하다면 이러한 세부과정은 별로 흥미롭지 않을 것이다. 먼저 matplotlib.pyplot 를 임포트한다.
1 | import matplotlib.pyplot as plt | cs |
다음으로, 시각화 함수를 정의한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | def visualize_data(positive_images, negative_images): # INPUTS # positive_images - Images where the label = 1 (True) # negative_images - Images where the label = 0 (False) figure = plt.figure() count = 0 for i in range(positive_images.shape[0]): count += 1 figure.add_subplot(2, positive_images.shape[0], count) plt.imshow(positive_images[i, :, :]) plt.axis('off') plt.title("1") figure.add_subplot(1, negative_images.shape[0], count) plt.imshow(negative_images[i, :, :]) plt.axis('off') plt.title("0") plt.show() | cs |
위 함수는 양성, 음성 이미지 샘플을 보여줄 것인데, 여기서 “positive” 라고 함은 “1” 또는 “True” 라벨을 가진 데이터를 의미하고, “negative” 는 “0” 또는 “False” 데이터를 가진 이미지를 말한다. 음성 샘플 (즉, 비행기가 포함되지 않은 이미지)이 필요한데, 그렇지 않으면 모델은 참고할 사항이 없어, 이미지의 미세한 존재만으로도 비행기를 포함하고 있다고 판단할 우려가 있기 때문이다.
visualize_data 함수의 내부 동작은 양성 샘플 이미지를 위에 그리고 같은 수의 음성샘플을 아래에 배열하게 된다. 그리고 이미지위의 텍스트는 라벨을 나타낸다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # Number of positive and negative examples to show N_TO_VISUALIZE = 10 # Select the first N positive examples positive_example_indices = (y_train == 1) positive_examples = x_train[positive_example_indices, :, :] positive_examples = positive_examples[0:N_TO_VISUALIZE, :, :] # Select the first N negative examples negative_example_indices = (y_train == 0) negative_examples = x_train[negative_example_indices, :, :] negative_examples = negative_examples[0:N_TO_VISUALIZE, :, :] # Call the visualization function visualize_data(positive_examples, negative_examples) | cs |

이미지가 흐릿한 것은 해상도가 20*20 이기 때문이다. 하지만 이에도 불구하고 양성 샘플에는 비행기의 모습이 보이고, 음성 샘플에는 비행기가 보이지 않는다. 나름 적절하게 작동하는 것으로 보인다. 음성 샘플에는 비행기의 일부분이 보이기도 한다. 양성 샘플의 비행기 크기는 전부 다르다. 어떤 경우에는 16~18 픽셀을 차지하기도 하고, 8~10 픽셀만 차지하기도 한다. 이제 ML 모델 생성에 대해 살펴보자.
Model Creation
머신러닝에서는 입력데이터 (X) 를 받아 결과 (y) 를 예측하는 것을 모델이라고 말한다. 모델은 주어진 데이터에 대해 최상의 가능한 결과를 만들어내기 위해 훈련 (또는 "fit") 을 하게 된다.
이제 만들려고 하는 모델은 합성곱 (Convolutional Neural Network, CNN) 이라고 불린다. 중요한 파트로 바로 넘어가자. 완전히 이해하지 못한다고 해서 좌절할 필요는 없다.
1 2 3 4 5 6 | # Imports from keras.models import Sequential from keras.layers import Activation, Dropout, Flatten, Dense, Conv2D, MaxPooling2D from keras.callbacks import EarlyStopping, TensorBoard from sklearn.metrics import accuracy_score, f1_score from datetime import datetime | cs |
케라스 관련 임포트문이 많이 보인다. 케라스 프레임워크 위에 CNN 을 구축할 것이다. 케라스는 TensorFlow, MXNet, 그리고 Theano 같은 백엔드 위에 구축되는 하이 레벨 패키지이다. 이 말은 케라스로 작성된 코드는 다른 백엔드로도 작성될 수 있다는 말이다. 하지만 이런 백엔드를 가지고 구축하는데는 더욱 많은 코드가 필요한 단점이 있다. 성능은 비슷하다고 보면 된다. 이런 이유로 케라스는 초심자가 실무형 코더에게 더 가치있는 프레임워크이다. 아래 이미지를 보자.

위 그림에서 보듯이 “Deep Learning”은 2개 이상의 레이어를 가진 신경망에 대해 말할 때 언급되는 하나의 분류라고 할 수 있다. 그럼 레이어는 무엇인가? 레이어는 기본적으로 연산의 단위이다.
모든 숫자에 5를 곱하는 “multiply by 5” 라고 불리는 레이어를 가지고 있다고 하자. 그리고 “multiply by 5” 레이어에서 나온 결과를 “multiply 10” 레이어로 보내 10을 곱한다. 이러한 CNN의 경우, 주레이어타입은 인풋에 곱하여 아웃풋을 만드는 “Convolutional Layer” 이다. 이에 대한 수학적인 설명은 생략하고 이 개념에 대해 깔끔하게 소개하고 있는 아래 그림을 보자. 여기서 파란색 이미지가 인풋이고, 녹색 이미지가 아웃풋이다.
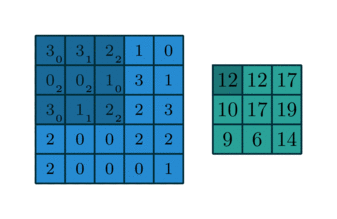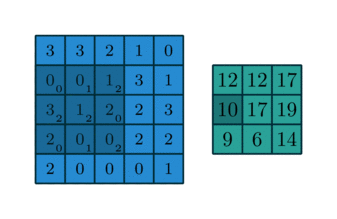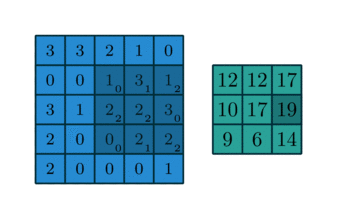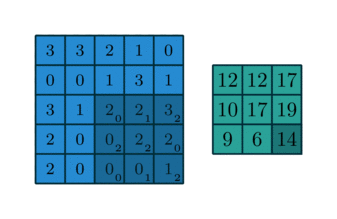
위와 같은 동작인 동시에 수없이 일어난다고 생각해보면, 합성곱 레이어에 대한 합리적인 이해가 가능할 것이다. 물론 다른 형태의 레이어도 존재한다. 예를 들어, “ReLu” 레이어는 모든 음수를 0 으로 변환한다. 애니메이션 이미지를 가로지르는 3x3 사각형을 “convolutional kernel” 이라고 부른다. 훈련하는 동안 CNN은 X 데이터를 레이어에 집어넣어 정확한 y 값을 예측하는 커널의 최적치를 학습하게 된다. 이러한 커널의 값을 학습가능한 모델 파라메터라고 생각할 수 있다. 수많은 커널이 있지만, 여기서는 논외로 한다.
먼저 하이퍼파라메터부터 정의하자. 하이퍼파라메터란 모델의 성능을 개선하기 위한 사용자 정의 값을 말한다. 훈련과정에서 모델 스스로 개선을 해나가는 모델 파라메터와 혼동을 일으켜서는 안된다.
1 2 | # Hyperparamater N_LAYERS = 4 | cs |
“N_LAYERS” 하이퍼파라메터는 CNN이 몇개의 합성곱 레이어를 가질 것인가에 대한 정의값을 말한다. 다음으로 케라스를 이용하여 모델을 정의해보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | def cnn(size, n_layers): # INPUTS # size - size of the input images # n_layers - number of layers # OUTPUTS # model - compiled CNN # Define hyperparamters MIN_NEURONS = 20 MAX_NEURONS = 120 KERNEL = (3, 3) # Determine the # of neurons in each convolutional layer steps = np.floor(MAX_NEURONS / (n_layers + 1)) nuerons = np.arange(MIN_NEURONS, MAX_NEURONS, steps) nuerons = nuerons.astype(np.int32) # Define a model model = Sequential() # Add convolutional layers for i in range(0, n_layers): if i == 0: shape = (size[0], size[1], size[2]) model.add(Conv2D(nuerons[i], KERNEL, input_shape=shape)) else: model.add(Conv2D(nuerons[i], KERNEL)) model.add(Activation('relu')) # Add max pooling layer model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(MAX_NEURONS)) model.add(Activation('relu')) # Add output layer model.add(Dense(1)) model.add(Activation('sigmoid')) # Compile the model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Print a summary of the model model.summary() return model | cs |
위의 코드를 전부 마스터할 필요는 없다. 위의 코드는 수백가지 가능한 네트워크 구조의 하나에 불과할 뿐이다. 하지만 “model.add()” 가 데이터를 전달하는 일련의 레이어를 만든다는 정도는 알아야 한다. Conv2D 레이어(케라스가 합성곱 레이어를 만드는지에 대한 것) 외에도 다수의 MaxPooling2D, Dense, 그리고 Activation 레이어와 같은 비합성곱 레이어가 이에 포함된다. 함수의 끝부분에서 어떻게 최적화하고 평가할지를 정의하는 컴파일을 하게 된다.
케라스를 통해 CNN 을 설계할 때, 일반적으로 다음의 절차를 따르게 된다.
“model = Sequential()” 를 통해 순차적으로 레이어를 더해가는 모델을 생성한다.
“model.add()” 을 이용하여 다수의 레이어를 모델에 더한다.
“model.compile()” 을 통해 모델 컴파일링
그럼 model.compile() 의 입력 부분에 대해 좀 더 살펴보자.
Loss loss 함수는 모델의 성공과 실패를 정의한다. 각각의 반복되는 훈련 동안, 이 함수를 이용하여 현재 성과를 평가하고, 이에 기반하여 모델의 파라메터를 개선하기 위해 손실을 계산한다. 이진 분류와 관련된 작업시에 Binary cross entropy 는 꽤 괜찮은 선택이다.
Optimizer 파라메터를 어떤 방식으로 (예를 들어, 큰 규모로 아니면 소규모로 수정해나갈 것인가?) 개선할 것인가를 정의한다. 여기서 사용하는 adam optimizer 의 경우 특히 강건하고, 효율적인 최적화를 위해 몇 가지 트릭도 제공한다. 이것또한 대부분의 딥러닝 모델의 표준적인 선택에 가깝다.
Metrics 는 훈련을 하는 동안 어떤 항목을 리포팅해줄 것인가에 대한 것이다. Accuracy 항목이 loss 보다는 모델의 현재 성능에 대한 인간친화적인 해석이 가능하도록 도와준다.
summary of the model architecture

https://cdn-images-1.medium.com/max/800/1*Gql4yKUFru7les67x-6e_Q.png
위의 요약은 아주 강력한 도구로 활용할 수 있다. “None” 이 모든 출력 형태의 첫 번째 차원임에 주의해야 한다. 왜냐하면 훈련하는 동안 많은 이미지를 단 한 번만 모델에 제공하지만 그 수를 정확히 정의할 수 없기 때문이다. 따라서 “None” 이 시나리오에서는 일종의 와일드카드에 가깝다고 볼 수 있다. 이 모델이 실제로 배포될 때 한 번에 하나의 이미지에 대해서만 예측을 하게 된다면 이 경우 None 값은 1 이 된다.
추가적으로, 출력형태는 최종적으로 (None, 1) 이 될 때까지 계속 변화한다. 최종 형태는 단일부동소수점값 형태로 모델의 최종 예측에 대해 알려준다 (예를 들면, 주어진 이미지에 비행기가 포함되어 있을 확률이 어떻게 되는가?).
그리고 각각의 레이어의 훈련가능한 파라메터의 수를 볼 수 있다. 모델을 훈련할 때 기본적으로 489,597개의 서로 다른 값을 가진다.
최종적으로 입력 이미지 사이즈와 앞서 정의한 모델 하이퍼파라메터를 전달함으로써 이 모델의 인스턴스를 실제로 생성한다.
1 2 | # Instantiate the model model = cnn(size=image_size, n_layers=N_LAYERS) | cs |
Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 18, 18, 20) 560 _________________________________________________________________ activation_1 (Activation) (None, 18, 18, 20) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 16, 16, 44) 7964 _________________________________________________________________ activation_2 (Activation) (None, 16, 16, 44) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 14, 14, 68) 26996 _________________________________________________________________ activation_3 (Activation) (None, 14, 14, 68) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 12, 12, 92) 56396 _________________________________________________________________ activation_4 (Activation) (None, 12, 12, 92) 0 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 6, 6, 92) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 3312) 0 _________________________________________________________________ dense_1 (Dense) (None, 120) 397560 _________________________________________________________________ activation_5 (Activation) (None, 120) 0 _________________________________________________________________ dense_2 (Dense) (None, 1) 121 _________________________________________________________________ activation_6 (Activation) (None, 1) 0 ================================================================= Total params: 489,597 Trainable params: 489,597 Non-trainable params: 0 _________________________________________________________________
Model Training
훈련은 ML 알고리즘이 파라메터를 개선하고 최적화를 착수하는 프로세스다. CNN 은 전형적으로 반복적 훈련 형태를 띄며, 모델은 매회마다 성능 개선을 꾀한다.
에포크(epoch) 는 훈련 데이터셋에 있는 모든 이미지를 한 차례 훈련하는 것을 말한다. 좀 더 분명히 말하자면 1,000개의 훈련용 이미지가 있고, 배치 사이즈가 100이라고 하자. 이 말의 의미는 각 에포크당 10번의 반복이 있다는 뜻이다. 왜냐하면 전체 훈련 데이터셋을 도는 동안 10개의 배치를 전달해야하기 때문이다. 훈련 하이퍼파라메터를 정의하자.
1 2 3 | # Training hyperparamters EPOCHS = 150 BATCH_SIZE = 200 | cs |
그러면 왜 데이터를 배치 형태로 관리하는 것인가? 이에 대한 대답은 다소 복잡하지만, 기본적으로 우리는 손실함수를 최적화하는 것을 기대하고 있다.그런데 전체 훈련 데이터셋을 한 번에 살펴보는 것으로는 손실함수를 최소화하는 목표를 달성하기 어렵다. 게다가 실제 사례를 보면 동시에 모든 데이터를 GPU 의 메모리에 집어 넣을 수도 없기 때문이다. 하지만, 한 번에 하나의 이미지에 대해서만 훈련하는 것은 계산상으로 보면 비효율적이다. 따라서 결국 배치 사이즈가 결국 그 사이의 일종의 타협점이 되는 셈이다.
다음으로, 조기종료(early stopping) 콜백을 정의하자. 콜백이란 간단히 설명하면 모델이 훈련하는 동안 체크인을 해주는 함수를 말한다.
1 2 3 | # Early stopping callback PATIENCE = 10 early_stopping = EarlyStopping(monitor='loss', min_delta=0, patience=PATIENCE, verbose=0, mode='auto') | cs |
훈련은 반복적인 과정으로, 매번 그 성과가 향상될수도 있지만 오히려 더 저조해질 수도 있는 것이다. 조기종료는 사용자 정의 시간 (PATIENCE 라는 하이퍼파라메터를 통해 에포크의 수로 정의된다) 동안 특별한 향상을 보이지 않으면 모델로 하여금 훈련을 그만두도록 지시하는 역할을 한다.
이제 텐서보드 콜백을 정의하자.
1 2 3 4 5 | # TensorBoard callback LOG_DIRECTORY_ROOT = '' now = datetime.utcnow().strftime("%Y%m%d%H%M%S") log_dir = "{}/run-{}/".format(LOG_DIRECTORY_ROOT, now) tensorboard = TensorBoard(log_dir=log_dir, write_graph=True, write_images=True) | cs |
텐서플로우 백엔드에 케라스를 사용하는 이들에게 텐서보드는 강력한 시각화 툴이다. 텐서보드는 모델의 성능을 훈련하는 동안 실시간으로 보여준다. 텐서보드는 다음과 같이 실행할 수 있다.
1 2 | (tfKeras) founder@hilbert:~/tfKeras$ tensorboard --logdir /home/founder/tfKeras/tensorlog TensorBoard 1.12.0 at http://hilbert:6006 (Press CTRL+C to quit) | cs |
위와 같이 실행한 후 브라우저를 열고 [your_ip]:6006 형태로 주소창에 입력하면 된다. 아무런 정보가 나오지 않을 수도 있다. 하지만 실제 훈련을 시작하게 되면 아래와 같은 아웃풋을 볼 수 있을 것이다.

마지막으로 위의 2가지 콜백을 리스트에 넣는다.
1 2 | # Place the callbacks in a list callbacks = [early_stopping, tensorboard] | cs |
이제 훈련 준비가 끝났다. 훈련을 시작하자.
1 2 | # Train the model model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, callbacks=callbacks, verbose=0) | cs |
<keras.callbacks.History at 0x7fbc743e2588>
model.fit() 함수는 훈련 이미지 (x_train), 라벨 (y_train), 에포크, 배치 사이즈, 그리고 콜백을 전달한다. GPU의 경우 이 과정에 대략 10분 정도 소요된다.
“Scalars” 탭으로 가면 2개의 측정항목이 있음을 알 수 있다. 앞선 텐서보드 스크린샷에서 볼 수 있듯이 “acc” 그래프는 점진적으로 1.0에 접근해간다. 반면 loss 그래프는 0에 접근해간다. 건강한 모델의 경우 이런 양상을 보인다.
대부분의 경우 loss 와 accuracy 는 동전의 양면이다. Loss 는 모델이 내부적으로 그 성과를 어떻게 평가하는지에 관한 것이다. 실수를 줄이기 위한 모든 노력은 loss 를 줄인다. 앞에서 암시했듯이 대부분의 사람들은 loss 를 줄이기보다는 accuracy 를 극대화한다는 아이디어가 이해하기 쉽다. 따라서 알고리즘이 그 정보를 사용하지 않더라도 accuracy 역시 보고되는 것이다. 그리고 추가적으로 모델의 세부적인 표현에 대해 알고 싶으면, “Graphs” 탭으로 이동하여 살펴보면 된다.

Model Evaluation
훈련이 끝나면 다음 코드를 이용하여 검증셋트에서 모델을 평가해야 한다.
1 2 3 | # Make a prediction on the test set test_predictions = model.predict(x_test) test_predictions = np.round(test_predictions) | cs |
바이너리로 결과를 반환하기 위해 점수를 반올림했다.
그리고 예측을 실측자료와 비교했다.
1 2 3 | # Report the accuracy accuracy = accuracy_score(y_test, test_predictions) print("Accuracy: " + str(accuracy)) | cs |
Accuracy: 0.98625
검증세트에 기반한 모델의 최종 성능을 보여준다. 본 가이드를 통해 훈련시킨 모델의 경우 Accuracy: 0.98625 를 기록했다. 모델이 검증에 실패한 이미지를 살펴보는 과정을 통해 보완해야하는 점을 찾는 과제가 남아있다. 아래는 검증에 실패한 이미지를 보여주는 코드이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import matplotlib.pyplot as plt def visualize_incorrect_labels(x_data, y_real, y_predicted): # INPUTS # x_data - images # y_data - ground truth labels # y_predicted - predicted label count = 0 figure = plt.figure() incorrect_label_indices = (y_real != y_predicted) y_real = y_real[incorrect_label_indices] y_predicted = y_predicted[incorrect_label_indices] x_data = x_data[incorrect_label_indices, :, :, :] maximum_square = np.ceil(np.sqrt(x_data.shape[0])) for i in range(x_data.shape[0]): count += 1 figure.add_subplot(maximum_square, maximum_square, count) plt.imshow(x_data[i, :, :, :]) plt.axis('off') plt.title("Predicted: " + str(int(y_predicted[i])) + ", Real: " + str(int(y_real[i])), fontsize=10) plt.show() visualize_incorrect_labels(x_test, y_test, np.asarray(test_predictions).ravel()) | cs |

학습모델 저장
1 2 3 | from keras.models import load_model model.save('airplane_image_classification_model.h5') print("Saved classifier to disk") | cs |
모델 아키텍쳐 보기
1 2 3 4 5 6 | from IPython.display import SVG from keras.utils.vis_utils import model_to_dot %matplotlib inline SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg')) | cs |

학습모델 불러오기
1 2 | from keras.models import load_model model = load_model('airplane_image_classification_model.h5') | cs |
정확도에 95% 가지는 의미에 대해서는 다음 링크 참조
How accurate is 95% accurate? m.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721
원문보기 https://medium.com/@kylepob61392/airplane-image-classification-using-a-keras-cnn-22be506fdb53